Circle-Circle Intersections
Looking at the past few years of ACM finals problems, there is a problem that frequently comes up, under many different guises. That problem is finding the points of tangency between two circles.
So, given two circles A and B, with radii rA and rB
each circle may have up to four points of tangency -- what are they for circle A?
There are two general ways of going about this problem, both of which rely upon the Pythagorean theorem. Both start out the same way. First, we take one of the lines of tangency we're interested in -- say, one of the outer ones:

Then, we note that if we shift the tangent line down along the line from B to P4, we now have a different, easier problem: finding the tangent lines between a circle and a point. The point is just the center of the smaller original circle, B, and the new circle is one with radius rA - rB, centered at point A.
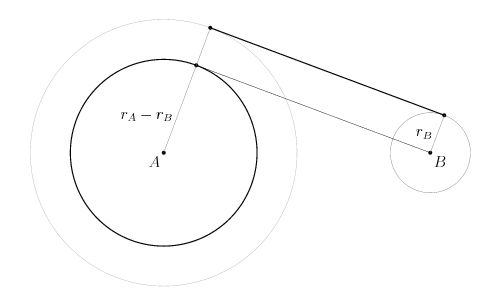
Now we have a nice, easy-to-use right triangle, with hypotenuse d (not shown above), and legs rA-rB and q. The unknown leg q is the distance between B and each point of tangency on the smaller circle centered at A. The Pythagorean theorem gives q = sqrt(d2 - (rA-rB)2);
Now, we have several ways of going about finding the tangent point on the circle A. One way is to use trigonometry to find the angle marked theta below; with it, one can directly reconstruct the coordinates for P3.
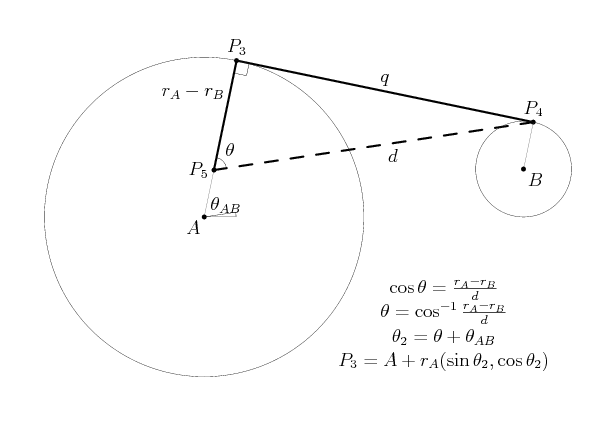
The steps needed to reconstruct P3 are given in the illustration above; to find the corresponding bottom tangent point, we use theta3 as (thetaAB - theta + 2pi). It's short to code, and elegant mathematically, but most programming articles will be quick to point out that trig functions are slow on a computer. Thus, we'd like an alternative approach, one that doesn't involve trigonometric functions.
Here is one approach, illustrated below: If we draw a line from B to P3 above, we get another right triangle, this time with side lengths rB, q, and the unknown (and unshown) hypotenuse s.
If we think of this hypotenuse s as being the radius of a circle centered on point B, it seems clear that the intersection of those two circles will occur on the outer tangency points of the circle A. However, this leaves us with yet a third problem to solve: calculating the intersection points between two circles.
Switching gears and backing up for a moment, consider the other intersection we are interested in, the "inner" intersection between circles A and B. Now, instead of subtracting the radius of B from that of A, we add the two together. The tangent line between the larger circle and point B is the line labeled q in the picture below; note carefully that this q is distinct from the q in the previous problem!
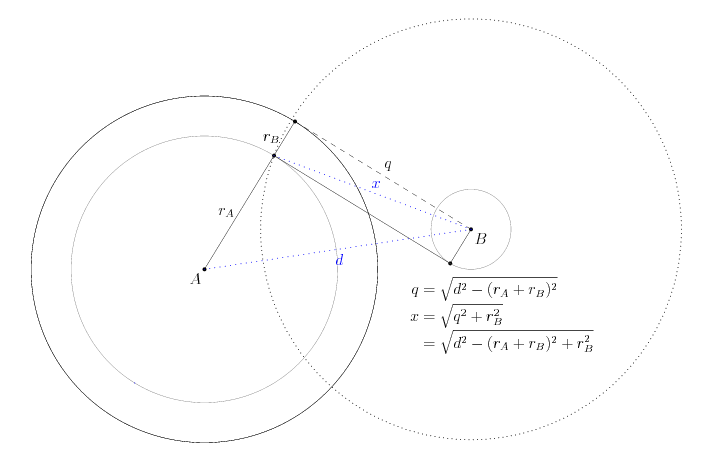
Shifting the whole line q downwards by rB gives us the desired tangent line between the two circles. However, we can do something else: draw just one of the endpoints of q down, giving the slightly longer line x, in blue. This is the distance between the point B and the two desired tangent points on the circle A. Now, finding the two inner tangent points on A is merely a question of finding the intersection between two circles: one centered at A with radius rA, and one centered at B with radius x. Finding the inner tangent points on B is similar, with x' = sqrt(q^2 + rA^2). And, finding the outer tangent points is similar again, merely subtracting instead of adding the radii when computing q.
As for the question of how to actually compute the intersection points between two circles, Paul Bourke has an excellent article on the process that is clearer than anything I could attempt. I do, however, wish to make one note. Paul nonchalantly uses the phrase "solve for a" and then magically produces the necessary equation. It's just simple algebra, but I think the technique is neat enough to write out explicitly (at least here).
Keep in mind, we know r, q, and d, and wish to find a (and therefore h).
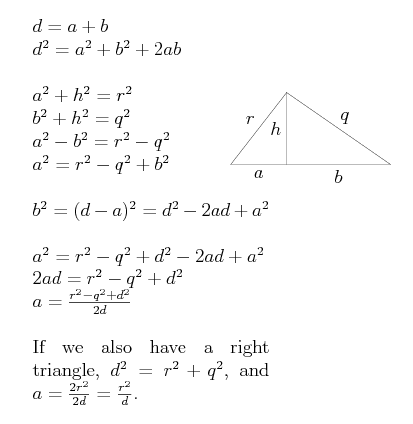
The Cost of Trigonometry
Earlier, I mentioned that "most programming articles will be quick to point out that trig functions are slow [...]." Originally, that had simply been "trig functions are slow," but I was curious about exactly how slow. Now, keep in mind that "slow" is a relative term, and that the ACM programming contest is about the selection of algorithms, not about micro-optimization. Points are awarded on a pass/fail basis, and faster programs don't get extra points. In the context of the ACM programming competition, then, a function that runs 50% slower but is twice as short is probably preferable to one that runs faster but takes longer to type in.
The biggest issue when benchmarking this sort of code is that, in absolute terms, a single trig function doesn't take very long to execute. Even if it takes, say, 200 times as long as adding two numbers, that's still only (say) one ten-millionth of a second. The resolution of most system timers is on the order of milliseconds, much too coarse for us.
On Windows, there are finer timers available, but that's not a portable solution, and it incurs function-call overhead. In my daily stumblings around the 'net, I recently came across something very interesting: a Pentium-specific assembly instruction called RDTSC. It returns the number of clock cycles that have elapsed since the system was last rebooted. Even for very fast machines, 264 clock cycles is about a thousand years.
Presumably, this is the "high resolution performance counter" referenced in the Microsoft documentation above. My Core 2 Duo is very nice in that it increments the TSC at a constant rate, regardless of whether the chip has been throttled in a low-power state.
Using code from an oldish Intel document, I set about timing two slightly different functions to compute circle-circle intersections. All optimizations were off, because that's how code is compiled for the contest. Microsoft's cl.exe version 15 was used. I had a number of interesting results:
- Finding the angle of a point using atan2 takes about 500 cycles.
- Finding the absolute value (length) of a complex number takes about a thousand cycles.
- Computing the norm (squared length) of a complex number takes about 70 cycles
- Computing the square root of a double takes about 70 cycles
- Computing the squared length of a vector using dot product, implemented in terms of complex multiplication, takes about 280 cycles.
- Computing two circle intersection points using trigonometry takes about 9500 cycles
- Computing two circle intersection points using simple geometry takes about 8200 cycles
While the simple geometry was slightly faster, it wasn't faster by much. Certainly, from a contest perspective, the speed difference wasn't enough to matter.
One interesting thing is that, when finding the length of a vector (or the distance between two points), the built-in std::abs() function for complex numbers is almost eight times slower than the naive implementation involving taking the square root of the norm. If you look at the implementation for abs, it has cases for one or both parts of the complex number being infinity or NaN, and it then does a relatively complex calculation in order to preserve numerical stability. However, since our output will be truncated to just a handful of decimal places anyways, the extra accuracy does us no good. Thus, it seems worthwhile to have a macro defining length(v) as sqrt(norm(v)).